- 純文字的資料處理
- 分割與擷取
- 搜尋與取代
- 正則表示式
- 中文資料的編碼
- 練習
2019/5/8
課程大綱
純文字的資料處理
strsplit
args(strsplit)
## function (x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE) ## NULL
strsplit("abc", "a")
## [[1]] ## [1] "" "bc"
strsplit(c("abc", "baca"), "a")
## [[1]] ## [1] "" "bc" ## ## [[2]] ## [1] "b" "c"
利用strsplit搭配中括號抓取資料
- 能不能利用
strsplit找出<author>...</author>之間的文字?
<fortune> <quote>Okay, let's stand up and be counted: who has been writing diamond graph code? Mine's 60 lines.</quote> <author>Barry Rowlingson</author> <context>in a discussion about the patent for diamond graphs</context> <source>R-help</source> <date>August 2003</date> </fortune> <fortune> <quote>Bug, undocumented behaviour, feature? I don't know. It all seems to work in 1.6.0, so everyone should downgrade now... :)</quote> <author>Barry Rowlingson</author> <context>NA</context> <source>R-help</source> <date>July 2003</date> </fortune> <fortune> <quote>I'm always thrilled when people discover what lexical scoping really means.</quote> <author>Robert Gentleman</author> <context>NA</context> <source>Statistical Computing 2003, Reisensburg</source> <date>June 2003</date> </fortune> <fortune> <quote>My institution has a particularly diabolical policy on intellectual property, especially on software.</quote> <author>Ross Ihaka</author> <context>NA</context> <source>R-help</source> <date>August 2003</date> </fortune> <fortune> <quote>If you imagine that this pen is Trellis, then Lattice is not this pen.</quote> <author>Paul Murrell</author> <context>on the difference of Lattice (which eventually was called grid) and Trellis</context> <source>DSC 2001, Wien</source> <date>March 2001</date> </fortune>
strsplit
x <- readLines("http://homepage.ntu.edu.tw/~wush978/rdataengineer/fortunes.xml")
. <- strsplit(x, "<author>")
- 在
.中(.是list)- 原文有
<author>的字串,會被分割為長度是 2 的字串 - 原文沒有
<author>的字串,長度是1
- 原文有
length(.[[1]])
## [1] 1
length(.[[3]])
## [1] 2
strsplit
- 寫迴圈處理
.tokens <- c()
for(.token in .) {
if (length(.token) == 2) stop("")
}
- 與R互動,看看
.token
.tokens <- c()
for(.token in .) {
if (length(.token) == 2) .tokens <- c(.tokens, .token[2])
}
.tokens
## [1] "Barry Rowlingson</author>" "Barry Rowlingson</author>" ## [3] "Robert Gentleman</author>" "Ross Ihaka</author>" ## [5] "Paul Murrell</author>"
strsplit
- 再用
</author>切一次
. <- strsplit(.tokens, "</author>") unlist(.)
## [1] "Barry Rowlingson" "Barry Rowlingson" "Robert Gentleman" ## [4] "Ross Ihaka" "Paul Murrell"
小挑戰
- 請用相同的作法,找出
x中的<date>與</date>之間的文字
download.file( "http://homepage.ntu.edu.tw/~wush978/rdataengineer/fortunes250.xml.gz", destfile = .tmp.path <- tempfile(fileext = ".gz"), mode = "wb" ) x250 <- readLines(.tmp.path)
- 請用相同的作法,找出
x250中的<date>與</date>之間的文字
strsplit的fixed參數
strsplit("a.b.c", ".")
## [[1]] ## [1] "" "" "" "" ""
strsplit("a.b.c", ".", fixed = TRUE)
## [[1]] ## [1] "a" "b" "c"
.是正則表示式的特殊字元,有特殊的含意fixed = TRUE之後,R會忽略正則表示式
搜尋 grep
grep(pattern = "author", x)
## [1] 3 10 17 24 31
grep(pattern = "author", x, value = TRUE)
## [1] " <author>Barry Rowlingson</author>" ## [2] " <author>Barry Rowlingson</author>" ## [3] " <author>Robert Gentleman</author>" ## [4] " <author>Ross Ihaka</author>" ## [5] " <author>Paul Murrell</author>"
grepl(pattern = "author", x)
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE ## [12] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE ## [23] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE ## [34] FALSE FALSE
取代 gsub
(. <- grep(pattern = "author", x[1:10], value = TRUE))
## [1] " <author>Barry Rowlingson</author>" ## [2] " <author>Barry Rowlingson</author>"
(. <- gsub(pattern = " <author>", replacement = "", ., fixed = TRUE))
## [1] "Barry Rowlingson</author>" "Barry Rowlingson</author>"
(. <- gsub(pattern = "</author>", replacement = "", ., fixed = TRUE))
## [1] "Barry Rowlingson" "Barry Rowlingson"
小挑戰
- 怎麼用上面的方式,找出名字中包含
Paul的人? - 尋找
x250中<author>與</author>中包含Paul的人
正則表示式:大絕招
正則表示式是一種描述文字模式的語言。 它不是單純依照應用歸納出來的工具,背後具有相當的數學基礎。 正則表示式的誕生,來自於美國數學家Stephen Cole Kleene在超過半個世紀之前的研究成果:Kleene (1956)。 目前各種程式語言中,幾乎都內建正則表示式,但是他們的語法主要分成兩個派系:
一種語法出自於電機電子工程師學會(IEEE)制定的標準 一種語法,則來自於另一個程式語言:Perl
正則表示是可以讓我們撰寫程式來自文字中比對、取代甚至是抽取各種資訊。以下我們將從簡單的應用開始介紹。
grep
grep("<author>.*Paul.*</author>", x, value = TRUE)
## [1] " <author>Paul Murrell</author>"
grep("<author>.*Paul.*</author>", x250, value = TRUE)
## [1] " <author>Paul Murrell</author>" ## [2] " <author>Paul Gilbert, Douglas Bates, and Brian D. Ripley</author>" ## [3] " <author>Paul Murrell</author>" ## [4] " <author>Gustaf Rydevik and Paul Gilbert</author>" ## [5] " <author>Paul R. Stanley</author>"
pattern參數中的"<author>.*Paul.*</author>".與.*是特殊字元.代表一個任意字元*代表前面的符號重複無限次.*代表任意長度的任意符號
子模式(sub-pattern),用(與)表示
m <- regexec("<author>(.*)</author>", x)
. <- regmatches(x, m)
.[1:5]
## [[1]] ## character(0) ## ## [[2]] ## character(0) ## ## [[3]] ## [1] "<author>Barry Rowlingson</author>" "Barry Rowlingson" ## ## [[4]] ## character(0) ## ## [[5]] ## character(0)
適當的利用sapply化簡程式碼
- 在字串處理時,常常需要對每一個list的element作挑選或計算長度
sapply(., length)可以得到每一個element的長度sapply(., "[", 2)可以得到每一個element vector的第二個element
(. <- .[sapply(., length) == 2])
## [[1]] ## [1] "<author>Barry Rowlingson</author>" "Barry Rowlingson" ## ## [[2]] ## [1] "<author>Barry Rowlingson</author>" "Barry Rowlingson" ## ## [[3]] ## [1] "<author>Robert Gentleman</author>" "Robert Gentleman" ## ## [[4]] ## [1] "<author>Ross Ihaka</author>" "Ross Ihaka" ## ## [[5]] ## [1] "<author>Paul Murrell</author>" "Paul Murrell"
sapply(., "[", 2)
## [1] "Barry Rowlingson" "Barry Rowlingson" "Robert Gentleman" ## [4] "Ross Ihaka" "Paul Murrell"
- 不熟悉的同學,仍然可以寫迴圈慢慢作
參考閱讀
練習
- 用正則表示式,找出x250中包含
Ripley的那行文字 - 尋找
x250中<author>與</author>中包含Ripley的人 - 找出所有出現過的作者,與他們的出現次數(還要用 and 做切割)
編碼問題
- 電腦的資料,最終都是0和1
- 怎麼把一連串的0和1解讀成數字或文字?型態
(. <- as.raw(17))
## [1] 11
- 這是 0 / 1 的十六進位表示法
11代表1 * 16 + 1
showBits <- function(r) stats::symnum(as.logical(rawToBits(r)), symbols = c("0", "1"))
showBits(as.raw(17))
## [1] 1 0 0 0 1 0 0 0
編碼問題
- 一個整數在R中有4個bytes(8個0/1)
- 一個bytes可以用兩個16進位表示,稱為
hex code
- 一個bytes可以用兩個16進位表示,稱為
| int | hex | bits |
|---|---|---|
| 0 | 00 | 00000000 |
| 1 | 01 | 10000000 |
| 2 | 02 | 01000000 |
| 3 | 03 | 11000000 |
| 4 | 04 | 00100000 |
| 5 | 05 | 10100000 |
| 6 | 06 | 01100000 |
| 7 | 07 | 11100000 |
| 8 | 18 | 00011000 |
| 9 | 19 | 10011000 |
| 10 | 1a | 01011000 |
| 11 | 1b | 11011000 |
| 12 | 1c | 00111000 |
| 13 | 1d | 10111000 |
| 14 | 1e | 01111000 |
| 15 | 1f | 11111000 |
| 16 | 20 | 00000100 |
| 17 | 21 | 10000100 |
| 18 | 22 | 01000100 |
| 19 | 23 | 11000100 |
| 20 | 24 | 00100100 |
| 21 | 25 | 10100100 |
| 22 | 26 | 01100100 |
| 23 | 27 | 11100100 |
| 24 | 38 | 00011100 |
| 25 | 39 | 10011100 |
| 26 | 3a | 01011100 |
| 27 | 3b | 11011100 |
| 28 | 3c | 00111100 |
| 29 | 3d | 10111100 |
| 30 | 3e | 01111100 |
| 31 | 3f | 11111100 |
| 32 | 40 | 00000010 |
| 33 | 41 | 10000010 |
| 34 | 42 | 01000010 |
| 35 | 43 | 11000010 |
| 36 | 44 | 00100010 |
| 37 | 45 | 10100010 |
| 38 | 46 | 01100010 |
| 39 | 47 | 11100010 |
| 40 | 58 | 00011010 |
| 41 | 59 | 10011010 |
| 42 | 5a | 01011010 |
| 43 | 5b | 11011010 |
| 44 | 5c | 00111010 |
| 45 | 5d | 10111010 |
| 46 | 5e | 01111010 |
| 47 | 5f | 11111010 |
| 48 | 60 | 00000110 |
| 49 | 61 | 10000110 |
| 50 | 62 | 01000110 |
| 51 | 63 | 11000110 |
| 52 | 64 | 00100110 |
| 53 | 65 | 10100110 |
| 54 | 66 | 01100110 |
| 55 | 67 | 11100110 |
| 56 | 78 | 00011110 |
| 57 | 79 | 10011110 |
| 58 | 7a | 01011110 |
| 59 | 7b | 11011110 |
| 60 | 7c | 00111110 |
| 61 | 7d | 10111110 |
| 62 | 7e | 01111110 |
| 63 | 7f | 11111110 |
| 64 | 80 | 00000001 |
| 65 | 81 | 10000001 |
| 66 | 82 | 01000001 |
| 67 | 83 | 11000001 |
| 68 | 84 | 00100001 |
| 69 | 85 | 10100001 |
| 70 | 86 | 01100001 |
| 71 | 87 | 11100001 |
| 72 | 98 | 00011001 |
| 73 | 99 | 10011001 |
| 74 | 9a | 01011001 |
| 75 | 9b | 11011001 |
| 76 | 9c | 00111001 |
| 77 | 9d | 10111001 |
| 78 | 9e | 01111001 |
| 79 | 9f | 11111001 |
| 80 | a0 | 00000101 |
| 81 | a1 | 10000101 |
| 82 | a2 | 01000101 |
| 83 | a3 | 11000101 |
| 84 | a4 | 00100101 |
| 85 | a5 | 10100101 |
| 86 | a6 | 01100101 |
| 87 | a7 | 11100101 |
| 88 | b8 | 00011101 |
| 89 | b9 | 10011101 |
| 90 | ba | 01011101 |
| 91 | bb | 11011101 |
| 92 | bc | 00111101 |
| 93 | bd | 10111101 |
| 94 | be | 01111101 |
| 95 | bf | 11111101 |
| 96 | c0 | 00000011 |
| 97 | c1 | 10000011 |
| 98 | c2 | 01000011 |
| 99 | c3 | 11000011 |
| 100 | c4 | 00100011 |
| 101 | c5 | 10100011 |
| 102 | c6 | 01100011 |
| 103 | c7 | 11100011 |
| 104 | d8 | 00011011 |
| 105 | d9 | 10011011 |
| 106 | da | 01011011 |
| 107 | db | 11011011 |
| 108 | dc | 00111011 |
| 109 | dd | 10111011 |
| 110 | de | 01111011 |
| 111 | df | 11111011 |
| 112 | e0 | 00000111 |
| 113 | e1 | 10000111 |
| 114 | e2 | 01000111 |
| 115 | e3 | 11000111 |
| 116 | e4 | 00100111 |
| 117 | e5 | 10100111 |
| 118 | e6 | 01100111 |
| 119 | e7 | 11100111 |
| 120 | f8 | 00011111 |
| 121 | f9 | 10011111 |
| 122 | fa | 01011111 |
| 123 | fb | 11011111 |
| 124 | fc | 00111111 |
| 125 | fd | 10111111 |
| 126 | fe | 01111111 |
| 127 | ff | 11111111 |
| 128 | 00 | 00000000 |
| 129 | 01 | 10000000 |
| 130 | 02 | 01000000 |
| 131 | 03 | 11000000 |
| 132 | 04 | 00100000 |
| 133 | 05 | 10100000 |
| 134 | 06 | 01100000 |
| 135 | 07 | 11100000 |
| 136 | 18 | 00011000 |
| 137 | 19 | 10011000 |
| 138 | 1a | 01011000 |
| 139 | 1b | 11011000 |
| 140 | 1c | 00111000 |
| 141 | 1d | 10111000 |
| 142 | 1e | 01111000 |
| 143 | 1f | 11111000 |
| 144 | 20 | 00000100 |
| 145 | 21 | 10000100 |
| 146 | 22 | 01000100 |
| 147 | 23 | 11000100 |
| 148 | 24 | 00100100 |
| 149 | 25 | 10100100 |
| 150 | 26 | 01100100 |
| 151 | 27 | 11100100 |
| 152 | 38 | 00011100 |
| 153 | 39 | 10011100 |
| 154 | 3a | 01011100 |
| 155 | 3b | 11011100 |
| 156 | 3c | 00111100 |
| 157 | 3d | 10111100 |
| 158 | 3e | 01111100 |
| 159 | 3f | 11111100 |
| 160 | 40 | 00000010 |
| 161 | 41 | 10000010 |
| 162 | 42 | 01000010 |
| 163 | 43 | 11000010 |
| 164 | 44 | 00100010 |
| 165 | 45 | 10100010 |
| 166 | 46 | 01100010 |
| 167 | 47 | 11100010 |
| 168 | 58 | 00011010 |
| 169 | 59 | 10011010 |
| 170 | 5a | 01011010 |
| 171 | 5b | 11011010 |
| 172 | 5c | 00111010 |
| 173 | 5d | 10111010 |
| 174 | 5e | 01111010 |
| 175 | 5f | 11111010 |
| 176 | 60 | 00000110 |
| 177 | 61 | 10000110 |
| 178 | 62 | 01000110 |
| 179 | 63 | 11000110 |
| 180 | 64 | 00100110 |
| 181 | 65 | 10100110 |
| 182 | 66 | 01100110 |
| 183 | 67 | 11100110 |
| 184 | 78 | 00011110 |
| 185 | 79 | 10011110 |
| 186 | 7a | 01011110 |
| 187 | 7b | 11011110 |
| 188 | 7c | 00111110 |
| 189 | 7d | 10111110 |
| 190 | 7e | 01111110 |
| 191 | 7f | 11111110 |
| 192 | 80 | 00000001 |
| 193 | 81 | 10000001 |
| 194 | 82 | 01000001 |
| 195 | 83 | 11000001 |
| 196 | 84 | 00100001 |
| 197 | 85 | 10100001 |
| 198 | 86 | 01100001 |
| 199 | 87 | 11100001 |
| 200 | 98 | 00011001 |
| 201 | 99 | 10011001 |
| 202 | 9a | 01011001 |
| 203 | 9b | 11011001 |
| 204 | 9c | 00111001 |
| 205 | 9d | 10111001 |
| 206 | 9e | 01111001 |
| 207 | 9f | 11111001 |
| 208 | a0 | 00000101 |
| 209 | a1 | 10000101 |
| 210 | a2 | 01000101 |
| 211 | a3 | 11000101 |
| 212 | a4 | 00100101 |
| 213 | a5 | 10100101 |
| 214 | a6 | 01100101 |
| 215 | a7 | 11100101 |
| 216 | b8 | 00011101 |
| 217 | b9 | 10011101 |
| 218 | ba | 01011101 |
| 219 | bb | 11011101 |
| 220 | bc | 00111101 |
| 221 | bd | 10111101 |
| 222 | be | 01111101 |
| 223 | bf | 11111101 |
| 224 | c0 | 00000011 |
| 225 | c1 | 10000011 |
| 226 | c2 | 01000011 |
| 227 | c3 | 11000011 |
| 228 | c4 | 00100011 |
| 229 | c5 | 10100011 |
| 230 | c6 | 01100011 |
| 231 | c7 | 11100011 |
| 232 | d8 | 00011011 |
| 233 | d9 | 10011011 |
| 234 | da | 01011011 |
| 235 | db | 11011011 |
| 236 | dc | 00111011 |
| 237 | dd | 10111011 |
| 238 | de | 01111011 |
| 239 | df | 11111011 |
| 240 | e0 | 00000111 |
| 241 | e1 | 10000111 |
| 242 | e2 | 01000111 |
| 243 | e3 | 11000111 |
| 244 | e4 | 00100111 |
| 245 | e5 | 10100111 |
| 246 | e6 | 01100111 |
| 247 | e7 | 11100111 |
| 248 | f8 | 00011111 |
| 249 | f9 | 10011111 |
| 250 | fa | 01011111 |
| 251 | fb | 11011111 |
| 252 | fc | 00111111 |
| 253 | fd | 10111111 |
| 254 | fe | 01111111 |
| 255 | ff | 11111111 |
rawVector
- R的
rawVector會用hex code來表示一連串電腦真正看到的值 charToRaw會把文字轉成代表該文字的真正的rawVector
charToRaw("a")
## [1] 61
showBits(charToRaw("a"))
## [1] 1 0 0 0 0 1 1 0
rawVector
- R的
rawVector會用hex code來表示一連串電腦真正看到的值 charToRaw會把文字轉成代表該文字的真正的rawVector
charToRaw("中") # 不同作業系統看到的結果不同
## [1] e4 b8 ad
showBits(charToRaw("中"))
## [1] 0 0 1 0 0 1 1 1 0 0 0 1 1 1 0 1 1 0 1 1 0 1 0 1
把0/1變成文字的規則: ASCII(American Standard Code for Information Interchange)
這種「把0/1轉換為文字的規則」又稱為「編碼」
30–>"0"41–>"A"61–>"a"
把0/1變成中文的規則: BIG5 / UTF-8
BIG5
0 0 1 0 0 1 0 1 0 0 1 0 0 1 0 1–>a4 a4–>"中"0 0 1 0 0 1 0 1 1 0 1 0 0 1 1 1–>a4 e5–>"文"
UTF-8
0 0 1 0 0 1 1 1 0 0 0 1 1 1 0 1 1 0 1 1 0 1 0 1–>e4 b8 ad–>"中"0 1 1 0 0 1 1 1 0 1 1 0 1 0 0 1 1 1 1 0 0 0 0 1–>e6 96 87–>"文"
錯誤的中文編碼
- 把BIG5當成UTF-8
[1] "\xa4\xa4\xa4\xe5"
- 把UTF-8當成BIG5 (on windows)
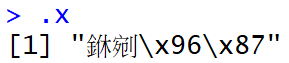
範例
https://www.google.com/search?q=成奶j學
. <- iconv(to="BIG5", x = "成功大學") charToRaw(.) ## [1] a6 a8 a5 5c a4 6a be c7 |
. <- iconv(to="BIG5", x = "成奶j學") charToRaw(.) ## [1] a6 a8 a5 a4 6a be c7 |
rawToChar(as.raw(0x5c)) ## [1] "\\" |
|
R 處理編碼的機制
- 原生的R,處理的不太好…
Encoding(x) <- "UTF-8" x
- 套件
stringi補上滿多相關功能 - 細節在作業
RBasic-07-...之中stringi::stri_encode
作業
- 請完成R語言翻轉教室 DataScienceAndR 課程的 02-RDataEngineer-01-Parsing 單元